Notebooks on real-world review classification example, Part-of-Speech tagging brief introduction, LSTMs recap, Notebook on Part-of-Speech Tagging with LSTMs, data preprocessing and training procedure best practices.
Notebooks on real-world review classification example, Part-of-Speech tagging brief introduction, LSTMs recap, Notebook on Part-of-Speech Tagging with LSTMs, data preprocessing and training procedure best practices.
Recurrent Neural Networks. Issues. Long-Short Term Memory Networks.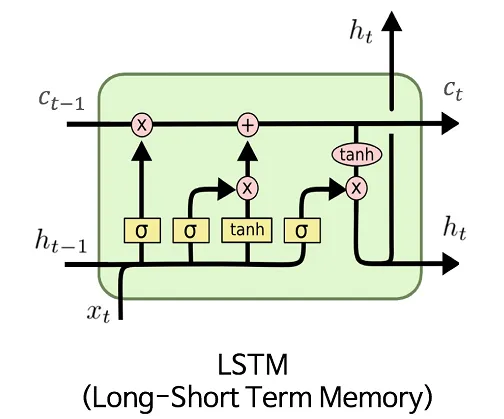
Negative sampling in the word2vec notebook. What is a language model? N-gram models (unigrams, bigrams, trigrams), together with their probability modeling and issues. Chain rule and n-gram estimation. Static vs. contextualized embeddings. Introduction to Recurrent Neural Networks.

Negative sampling: the skipgram case; changes in the loss function. Homework 1 assignment.
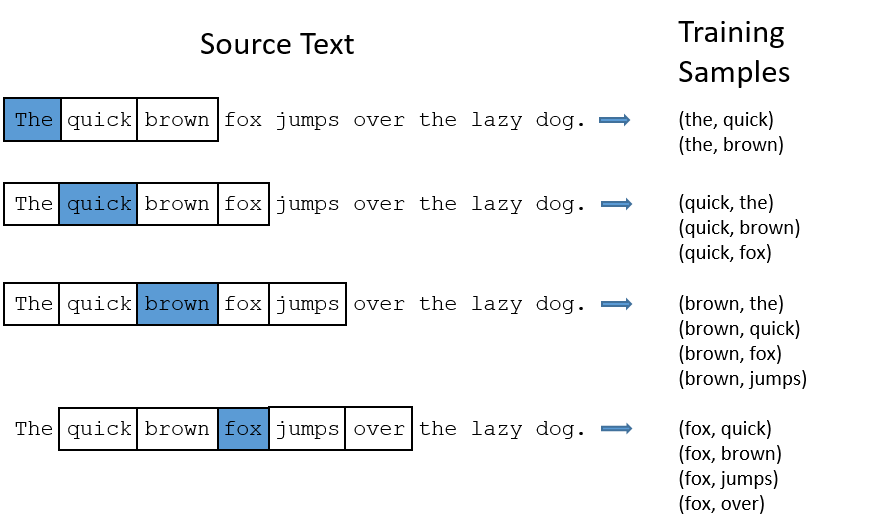
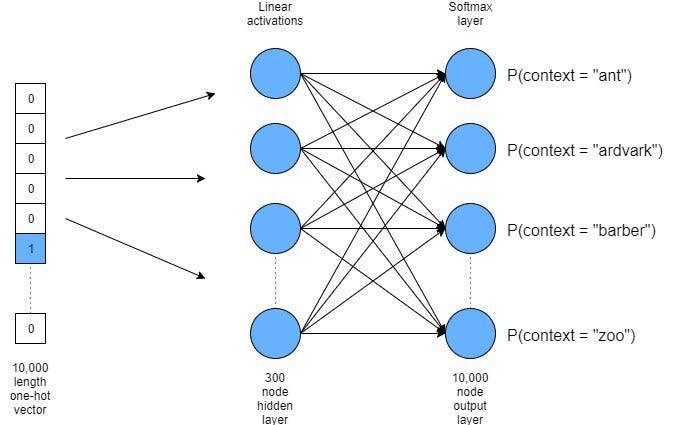
Word representations. Word embeddings. Word2vec (CBOW and skipgram), PyTorch notebook on word2vec.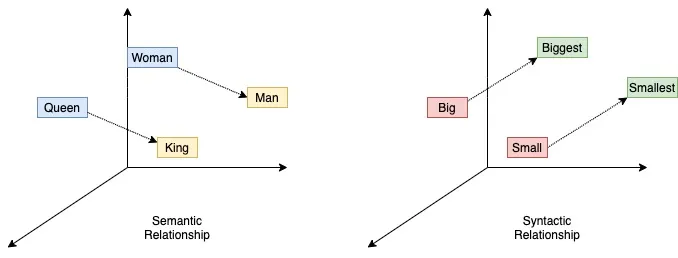
Recap of the Supervised Learning framework, hands on practice with PyTorch on the Language Detection Model: tensors, gradient tracking, the Dataset and DataLoader class, the Module class, the backward step, the training loop, evaluating a model.
Introduction to Supervised, Unsupervised & Reinforcement
Learning. The Supervised Learning framework. From real to computational:
features extraction and features vectors. Feature Engineering and
inferred features. PyTorch. Introduction to Colab notebooks and first part of the PyTorch hands-on.
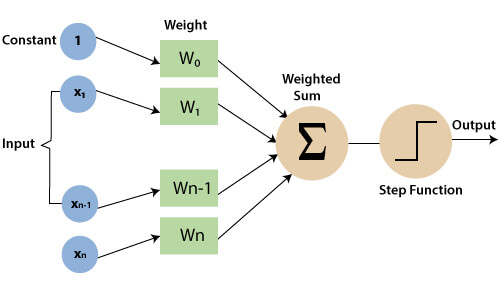
Basics of Machine Learning for NLP. Probabilistic classification. Logistic Regression and its use
for classification. Explicit vs. implicit features. The cross-entropy
loss function.

Introduction to the course. Introduction to Natural Language Processing: understanding and generation. What is NLP? The Turing Test, criticisms and alternatives. Tasks in NLP and its importance (with examples). Key areas and publication venues.
